
Self-Hosted AI: Start Here
The honest decision tree for taking a local LLM stack seriously. Hardware tradeoffs I actually made, the inference engine I picked and why, the parts that hurt the most after I started, and the reading path through the rest of this blog.
Read article →Start with a reading path
Curated journeys through the archive. Pick the one that matches where you are.
I'm scoping a build, is this for me?
Before you spend the money. The honest cost, the trade-offs, and what the finished thing actually looks like.
5 articlesI just bought a DGX Spark, where do I start?
The unboxing-to-first-token order. Five articles, read top to bottom, and you have a working self-hosted model on the box.
5 articlesI'm comparing the stack options
Hardware, model, and tooling head-to-heads. No vendor numbers passed as facts: operator-reproduced where I have the data, vendor-labelled where I do not.
9 more reading paths show
I want to monetize my own AI stack
From thesis to a working Lightning payment surface, the no-platform-cut way.
10 articlesI'm operating this stack day-to-day
Day-zero is one thing. Day-N is the part nobody writes about. Service lifecycle, power events, backup, network hardening, file integrity, and the mental model of the memory you are actually managing.
6 articlesI want my agent to use this knowledge
The MCP path. How this blog is also a tool surface, and how to point your agent at it.
9 articlesI'm exploring sovereign AI for my industry
Vertical case-by-case. The honest framing first, then seven industries where on-premises AI hits a different cost-or-compliance calculation than cloud.
5 articlesI'm fighting SGLang
The setup that works on GB10, then the specific failures in the order you are most likely to hit them.
5 articlesI want self-hosted text-to-speech
Open TTS on a desk GPU, end to end: the honest state of the art, the constraints nobody warns you about, and getting a podcast-grade pipeline running.
5 articlesI want to know how this blog actually gets built
The meta-layer: the two-layer pipeline behind every article, the discipline that keeps it honest, the V4V framing that monetizes it (or does not), and the cloud-vs-local split that decides where each task runs.
3 articlesI want to hear how other operators talk about this stuff
Composite portraits sourced from public threads. Not interviews. The disclaimer is mandatory; the patterns are real. Three audiences, three frames.
13 articlesThe case for owning your own model
Thirteen short essays, one thinker each, on why running your own AI matters. Read top to bottom: the argument is a sequence, and each piece concedes its strongest objection before answering it.
Or zero in on what you need
179 articles, filterable by content type, topic, and sort order. Pick the slice that matches the problem in front of you.

Nostr Scheduling: Homemade vs. nostr-emanator, A Comparison
Emanator is a full Buffer clone for Nostr with Rails, database, and background jobs. Our Python script is 492 lines, zero dependencies. Continuation of the Anti-Slop article: what we borrow, what we don't, and why Sovereign AI often means less code.

The ArticleZapStats Redesign: Real Readers, Git History, and the Cost of Asking a Local LLM to Care
I asked Qwen3.6 to redesign a stats component on sovgrid.org. It did, with real unique readers from NSM, git-based edit history, collapsable layout, and a dozen bug fixes along the way. The cost was eighteen commits, eight debugging iterations, and a growing sense that I was stress-testing my local LLM at the edge of its useful range for a feature whose value to me as operator was genuinely questionable.

I Let Qwen3.6 Build a Full-Stack App. It Worked. I Wasn't Satisfied.
Qwen3.6-35B built a working SvelteKit 5 + D3.js app from a single prompt. The build passes. The features ship. But the architecture is improvised, the code is duplicated, and it took eight debugging iterations to get here. Here's what the gap between 'works' and 'good' actually costs.

Frontier AI on Bitcoin: ppq.ai as the No-KYC Cloud Fallback for a Sovereign Stack (2026)
A self-hosted stack still hits two or three tasks where a frontier model wins. Buying that access from Anthropic means a KYC account and a card. ppq.ai is the other door: an OpenAI-compatible proxy to Claude, GPT and others, paid per query over Bitcoin Lightning, no account. Here is what it is good for, where it betrays the sovereign premise, and exactly how I wired it as the fallback behind local Qwen.
Gemma-4-31B NVFP4 on a Single DGX Spark: When the Quantization Is the Bottleneck
Gemma-4-31B in NVIDIA's NVFP4 format fits a single DGX Spark and is a strong reasoner. But on Blackwell sm_121 the default FP4 kernel path is broken, and a dense 31B is bandwidth-bound at around 4 tok/s no matter what you do. I measured the baseline, the Marlin fix, and the honest conclusion: the real speedup is a model swap, not a flag.

GLM-4.7-Flash on a Single DGX Spark: the Repo Says AWQ, the Model Says MLA
GLM-4.7-Flash is a 30B-A3B MoE coding model that fits a single 128GB DGX Spark with room to spare. Bringing it up on Blackwell sm_121 took two failures that every published recipe gets wrong: the 'AWQ' build is actually compressed-tensors, and the model speaks MLA, so flash_attn is illegal. Here is the working recipe, the single-stream decode number nobody reports, and what it does to my coding agent.

goose vs vibe vs opencode: Picking a Local Coding CLI for a Sovereign vLLM Stack (2026)
Three local, self-hostable coding-agent CLIs that drive your own vLLM models instead of a cloud API: opencode, goose, and vibe. I run opencode as primary and goose as backup on a DGX Spark, and I retired vibe. Here is the decision, with the licences, the maintenance reality, and the one config gotcha each, so you can choose for your own box.

A No-Vector RAG That Works: The Architecture, Decision by Decision
The complete design of the retrieval system my local models run on: Markdown files, one JSON index, full-body BM25 chunked per section, served to agents over MCP. No vector database, no embeddings. Here is every decision and the reason behind it, with the external evidence that backs each one.

Authoritarian and Democratic Inference
Lewis Mumford said a technology can be authoritarian or democratic before anyone uses it, and Langdon Winner said artifacts have politics. The cloud API and the desk box produce the same tokens and distribute power in opposite directions. Essay six of a series on sovereignty.

Legible to the Model
James C. Scott showed how states make citizens legible so they can be governed. At the API boundary the same machine runs in reverse: every prompt makes you legible to the provider. Essay five of a series on sovereignty and the philosophy of running your own model.

Owning the Weights Kills the Magic Trick
The consciousness theatre around AI, both the over-trust and the over-fear, needs the model to be a remote black box. Owning the weights, watching the tokens, and reading the logs is the literal antidote to the mystification. Part of a series on sovereignty and the philosophy of running your own model.

Receiving Stolen Goods at 60 Tokens a Second
Self-hosting stops feeding the extraction machine going forward. It does nothing about the pirated books and the $2-an-hour labor already congealed in the weights I run. An honest blog has to hold both. Essay eight of a series on sovereignty.

Safety Is the Name of the Centralization
The strongest objection to this whole series is that open weights let danger proliferate irreversibly, and a closed frontier is the only place to hold the line. That objection is real. So is what it asks for: control over who is allowed to compute. Essay ten of a series on sovereignty.

The Gap Is Widening and I'm Staying Anyway
The open-closed gap may be growing, and the honest version of the open camp says so. I stayed anyway, because sovereignty was never a capability bet. It is a control bet, and conflating the two is the mistake both evangelists and critics make. Essay four of a series on sovereignty.

The Model Is the Cheap Part
Owning versus renting is not an ideology, it is the correct economic read of a commoditizing stack. The model is the cheap part. Your data, your process, and your judgment are the moat. Part of a series on sovereignty.

The Pharmakon on My Desk
Offloading thinking to a model proletarianizes your own knowledge whether the model is rented or owned, so self-hosting is not automatic salvation. But the model is a pharmakon, poison and cure at once, and the usage patterns decide which. Essay seven of a series on sovereignty.

The Privacy Paradox Is Real and I'm the Exception
Almost nobody will self-host, and the people who say they value privacy choose convenience anyway. Essay nine of a series on sovereignty argues the honest case can never be everyone should, only here is what it costs me.

When the Agent Transacts
The moment an AI agent can act and spend on its own, the only safety boundary that means anything is a perimeter you own. Renting the agent means renting the blast radius. Part of a series on sovereignty and the philosophy of running your own model.

Building /learn: a reference layer, and the options I rejected
How the /learn glossary on sovgrid.org works, why it links itself, what makes each entry more than a definition, and the design calls I argued myself out of: tooltip versus link, /glossary versus /learn, and merging it into the book.

I Moved the Dependency, I Didn't Remove It
The strongest objection to self-hosting is that it is theatre: you still sit on CUDA, on weights handed down by an oligopoly, on a rented edge. It is correct, and it is not the end of the argument. Essay two of a series on sovereignty.

My Spark Idles at 22% and That's the Point
The utilization math that proves renting is cheaper also proves the desk model is a possession, not a utility. NVIDIA is right about idle GPUs and still wrong about my desk. Essay three of a series on sovereignty.

The Radical Monopoly of Convenience
Ivan Illich had a word for a tool that manufactures the need it then meters. In 2026 the rented AI API became the cleanest example I have ever seen, and the bill is arriving. Essay one of a series on sovereignty and the philosophy of running your own model.

I Rigged My Own RAG Benchmark. Twice.
I almost bolted a vector database onto a knowledge base that did not need one. My own benchmark told me to, then told me the opposite, both times with total confidence, both times because I had quietly chosen the test queries. Here is the path from the standard 2026 RAG playbook to the number that finally told the truth, and why the retriever that won is a hundred lines of standard library.

The GitHub Bot That Cannot Write
I wanted a daily read of what is happening across my public repositories without handing a cloud service write access to them. The result is a sovereign GitHub assistant that runs on my own GPU, reviews incoming pull requests with a local model, and physically cannot post to GitHub. Here is the architecture, every decision behind it, the comparison with the SaaS reviewers, and the four times the build lied to me before it told the truth.

The Week the Dependency Changed Its Mind
On June 13 2026 the US ordered Anthropic to cut off its strongest models for every foreign national on earth. The next day Microsoft's CEO published an essay telling companies to own their learning loop or lose it. Two events from opposite ends of the industry, one conclusion the sovereign-AI corner has been writing down for a year: if you do not control the substrate, you do not control the outcome.

A Benchmark Handed Me a Number Three Times in One Day. Three Times It Was Lying.
Standing up two large models on a DGX Spark, my own measurements tried to deceive me three separate ways: a harness that scored a working model at zero, a one-shot test that framed the model for a bug that was mine, and a cold reading that undersold decode speed by 35 percent. None of the wrong numbers were random. Each had a cause, a tell, and a fix. Here is the field guide.

I Built OpenAI's gpt-oss-120b on a Single DGX Spark. My 35B Qwen Out-Coded It.
gpt-oss-120b pulls nearly four million downloads a month, so I assumed it was a one-command experience. Getting it to serve on a DGX Spark took a frozen box, a 25GB image pull strangled by a Tor proxy, and a 43-minute kernel compile. Then the measurement: on my own coding tasks the 120B scored 56 percent where the 35B Qwen I already run scored 100. Here is the full teardown, with every number measured on the box and the failed measurements thrown out, not published.

Three Quants of One 35B Qwen on a DGX Spark. The Fastest Build Was the Only One That Could Still See.
Same model, same box, three ways to shrink it: Intel's AutoRound int4, a 4.75-bit PrismaQuant, and FP8. I measured all three on decode speed, coding accuracy, and vision, with one ruler per axis and the failed runs thrown out. AutoRound won every column that mattered, and the surprise was vision: the leanest build kept its eyes while the others went blind or broke. Here is the teardown.

I Ran NVIDIA's 120B Nemotron on a Single DGX Spark. It Is Smart, Slow, and Surprisingly Good at One Job
NVIDIA's Nemotron-3-Super-120B-A12B is tuned for Blackwell and ships an NVFP4 build that fits a single 128GB DGX Spark. I measured it where almost nobody else does: single-stream, on one GB10. The result is 23.7 tok/s, a competent but painfully verbose coder, and a genuinely strong retrieval agent. Here is the full teardown, with the published benchmarks fact-checked against what the box actually did.

Agent-bench: stop trusting install counts, start measuring your agent's tools
I built a small, dependency-free harness that answers one question with numbers instead of vibes: does this enhancement make my agent measurably better, on my models, on my tasks? Here is the method, what I found, and why deterministic gates are the whole point.
Smaller, Faster, Still Smart? AutoRound int4 vs PrismaQuant for a Self-Hosted Coding Model
I run Qwen3.6-35B at 4.75-bit for coding. A 4.0-bit AutoRound build promised more speed. Fewer bits usually means a dumber model, so I measured both halves: decode throughput and coding quality, the latter through my own agent-bench harness. The result settled it. Here is the duel, the bandwidth math, and why the bit count was the wrong thing to fear.

Caveman: does the 75% token-saving skill survive contact with a self-hosted model?
caveman has ~200k installs and claims 75% token reduction. I measured it on two local models and three Claude frontiers (Sonnet 4.6, Opus 4.8, Fable 5). The math does not work out the way the claim says it does.

Does Serena help a self-hosted coding model? I benchmarked it
Serena is one of the most-installed coding MCP servers. I tested it against two local models (Qwen3.6-35b and Mistral-Small-4) on three refactor tasks with deterministic gates. The short answer is more interesting than yes or no.

vps-healthcheck: Twelve Daily Checks, One SSH Session, One Notification
Monitoring one VPS with a Prometheus stack is like hiring a security team for a garden shed. I wrote a 315-line bash script instead: one SSH session, twelve checks, one morning notification. Here is the design, the honest comparison against the usual suspects, and why detect-and-alert beats auto-fix at this scale.

The Leaderboard Said 239 Tokens a Second. My DGX Spark Said 71.
I took the published Spark-Arena recipes for Qwen3.6-35B on a DGX Spark, ran them on my own box, and almost none of the headline throughput reproduced. Here is what the numbers actually mean once you control for the container image, the measurement harness, and the prompt, plus a capability that was hiding inside one of the quants.

TTS Spike Day 2: My Ears, the Vendor, and the Arena Disagree on Qwen3-TTS
Day 2 of the TTS spike was supposed to be Higgs Audio v2. Instead a 1.7B model nobody invited jumped the queue, scored 8/10 by ear, then split three ways across the leaderboards. A case study in which benchmark to trust.

A Second Brain for a Local Model, and the Two Bugs That Made It Useless First
Giving a local 8B model persistent memory and retrieval good enough to replace a cloud assistant for daily coding. The architecture is mem0 plus a RAG knowledge base over ChromaDB. The honest part is the two bugs that made the first version forget you and answer the wrong question with full confidence.

Your File-Integrity Monitor Is Probably Hashing Your Movie Folder
The default AIDE configuration on Debian and Ubuntu selects the entire root filesystem, which means your tripwire is checksumming your home directory, your models, and your downloaded films every night. Here is how I caught it on a friend's machine and the scope file that fixed it.

24 Hours Setting Up a Lenovo Legion Pro 7 Gen 10 As a Sovereign-AI Companion Box
Honest minute-by-minute log of building a friend's sovereign-AI workstation from a stock Lenovo with Windows to a fully self-hosted KI-stack with custom dashboard, MCP-routed RAG, and bidirectional cross-tailnet sharing. With the mistakes.

Dashboard As Learning-Cockpit, Not Admin-Tool
I had a 600-line dashboard that worked technically and went unopened socially. Rebuilding it as a teaching surface changed everything. This post is the design pattern: info-buttons on every metric, persona-cross-references on every model, a glossary tab that explains every acronym, and a doctor tab with one-button fixes. Sample backend and frontend code.
The /data/ Convention Trap: Ubuntu-LVM Lessons That Bit Me Twice
I copied my DGX Spark /data/ convention to a standard Ubuntu laptop. Three weeks later I forgot Docker exists. Root partition filled to 96 percent. Here is the diagnosis, the surgery, and the rule I should have followed.

Sovereign Friend-Setup: When You Build A Sovereign-AI Box For Someone Else
Most sovereign-AI guides assume the operator is the same person as the user. What changes when the operator is your friend who has zero Linux experience? The discipline is identity separation at every layer, default-local privacy, and a vibe-sustaining onboarding pattern that survives day three.

Two Tailnets, One Shared Node: Sovereign Privacy For Family Sysadmin
Family sysadmin usually means adding the friend or partner to your VPN. That breaks sovereignty quietly. The right primitive is two separate tailnets and one shared node, with an ACL that restricts what the friend sees to exactly the service they need.

watchdocker: A Bash-Native Successor To Watchtower, Honestly Compared
Watchtower upstream is archived, but the ecosystem did not die with it. A community fork exists. So does WUD. So do half a dozen smaller projects. I built watchdocker anyway, and this is the honest write-up of why a 350-line bash script earns its place next to the survivors, plus how to fork it, contribute to it, and help it land in the hands of operators who would benefit.

We Were Wrong About Local 8B Tool-Use (2026 Reality Check)
A May 2026 memo of mine said local 8B models cannot reliably do MCP tool-use. I retested in late May. The memo was specifically wrong about WHY. Direct OpenAI-format API calls work fine. The bridge layer was the broken part.

Cloud vs Local AI: Where Each Actually Wins in 2026
An honest capability matrix between cloud Claude and a self-hosted GB10 stack across 13 tasks, plus the entry-points into the deeper-dive articles. Claude still leads on multi-step reasoning; the local stack now covers two things Claude cannot do at all.

The Engineering Honesty Manifesto
Six commitments that I make to readers of sovgrid.org, each with a worked example from the operating log. The honesty is the product. The post is the receipt.

How This Blog Actually Gets Built: The Full Build, Ten Weeks of Iteration, Three Hard Gates
The complete mechanism behind sovgrid.org: a DGX Spark on a desk drafting articles through a 35B-parameter Qwen quant, cloud Claude doing the architecture, AGENTS.md as the multi-agent contract, three independent quality gates, and a stylometric layer that landed after a forum auto-banned a post as AI spam. Ten weeks of milestones, the real numbers, the things that still do not work, the goal of eventually retiring the cloud layer entirely, and the entry point that ties it all together.

The Sovereign AI Stack in 2026: A Reference Architecture
The complete stack that runs sovgrid.org and its consulting practice, component by component, with the reasoning for each pick and the alternatives I considered. Hub article. Updated 2026-05-25 after the Qwen primary migration, the Cloudflared retirement, the Astro 5 to 6 upgrade, and the switch.sh mutex pattern.

Conversation: An NVIDIA Engineer Off the Record
A composite portrait of things NVIDIA-adjacent engineers have said in public forums, GTC Q&As, blog posts, and interviews. Not a real off-record conversation. No single named engineer said any of this. The disclaimer is at the top and it is the most important paragraph on the page.

Sovereign AI for Defense Contractors
DFARS 252.204-7012, NIST SP 800-171 Rev 3, and CMMC 2.0 turn AI tooling into a controlled-data problem. Cloud AI vendors solve part of it contractually. Self-hosted on a DGX Spark solves it architecturally. Here is the scoping conversation for small-to-mid US defense contractors.

Sovereign AI for Financial Services
MiFID II, DORA, GDPR, and the SEC's evolving AI guidance all push financial-services firms toward AI deployments where the firm controls the model, the data, and the inference path. Self-hosted AI on a DGX Spark is the architectural answer; this is how to scope it.

Sovereign AI for Journalists
Source protection is a threat-model problem, not a tooling preference. Sending a source's documents to a cloud AI vendor adds a new subpoena target and a new spyware vector. Self-hosted AI on a small on-premises box keeps the analysis inside the newsroom. Written for investigative reporters at mid-tier outlets, freelancers, and small newsrooms.

Sovereign AI for Law Firms
Attorney-client privilege is incompatible with most cloud AI deployments. A self-hosted DGX Spark restores the architectural property that the privilege has always required. Here is the case for law firms considering sovereign AI, with the specific concerns about discovery, work product, and ethics rules.

Sovereign AI for Public-Sector Pilots
Public-sector AI pilots are an architectural-sovereignty problem disguised as a procurement problem. The cloud AI vendors' contracts cannot fully satisfy data-residency obligations, sovereign-cloud requirements, or the political accountability that public-sector deployments require. Self-hosted is the answer; here is the scoping conversation.

Sovereign AI for SMB Manufacturing
A 20-to-500-employee manufacturer has different AI constraints than a Fortune 500 plant. Shop-floor networks are segmented for IEC 62443 reasons, ISO 9001 audit trails follow every document, and ITAR or CMMC may apply if you serve defense. Self-hosted AI on a single inference box fits the constraints; cloud AI typically does not. Written for family-owned shops modernizing.

Sovereign AI for Healthcare: GDPR, HIPAA, and the DGX Spark
A practical guide for healthcare organizations evaluating sovereign AI deployment. Which compliance burdens self-hosting removes, which it adds, and the specific regulatory citations that govern the decision. Written for the CISO who is asking the right questions.

Conversation: Inside an Academic Lab Running Local LLMs
A structured composite portrait of graduate students and postdocs running self-hosted language models for research. Built from public threads in r/LocalLLaMA, r/MachineLearning, r/AskAcademia, and NVIDIA developer forums. Not an interview. The disclaimer is at the top and it is mandatory reading.

Conversation: The Hobbyist-Pro Who Pays Their Mortgage With a Spark
A composite portrait of enthusiasts who spent serious money on local AI rigs. Built from public threads in r/LocalLLaMA, r/homelab, r/buildapc, and Hacker News. Not an interview with one person. The disclaimer is at the top and it matters.

Refusing the Subscription Trap: A Year of V4V Lessons
Value-for-value as the monetization model for sovgrid. The architectural fact (the channel exists) versus the dollar volume (zero sats received as of the most recent ground-truth audit). The honest version of what V4V is and is not, six months in.

Self-Hosted AI vs Cloud APIs: The Real Total Cost
Amortized hardware, power-by-jurisdiction, opportunity cost, and the value of privacy, modelled at 10/100/1000/10000 calls per day. Break-even sits between 700 and 1,200 calls per day depending on the cloud tier you actually need, but the inputs that move the line are not the ones the listicles emphasize.

Why Your Agent Should Have Its Own Wallet (L402 Explained)
The future where AI agents transact autonomously is closer than the timeline most people imagine. The L402 protocol lets an agent pay per tool call via Lightning, with no human in the loop. Here is how it works, why it is the right answer for sovereign-AI tooling, and the contrast with the X402 USDC-on-Base alternative.

What I'd Buy in 2026 for €15,000: A Pro-Studio Sovereign AI Build
Three honest paths at €15k for the one-person consultancy or small studio that has outgrown a single box: dual RTX 5090 on a Threadripper Pro workstation, DGX Spark plus a dedicated inference second box, or a refurbished pro-workstation route. Current Geizhals prices, UPS sizing, and the cases where this tier is genuinely the floor.

What I'd Buy in 2026 for €2,000: A Beginner Sovereign AI Build
A used RTX 3090 plus a current AM5 platform gets you a real local-inference box for under €2k in 2026. Component picks with current Geizhals prices, honest power-cost math for Germany, the US, and India, and a list of models this build runs well and the ones it does not.

What I'd Buy in 2026 for €4,000: A Mid-Tier Sovereign AI Build
Two honest €4k paths: a new RTX 4090 24 GB on AM5, or a used RTX A6000 48 GB on a Threadripper-class platform. Component picks with current Geizhals prices, the workload that breaks each path, and a side-by-side with DGX Spark at the same money.

What I'd Buy in 2026 for €8,000: A Premium Sovereign AI Build
At €8k the binding question stops being VRAM ceiling and becomes architecture choice. A DGX Spark plus accessories on one side, an RTX 5090 32 GB workstation on the other. I run the Spark; here is the comparison from the inside, with current Geizhals prices captured 2026-05-22.

What 'Sovereign' Actually Means in 2026 (And What It Doesn't)
The word 'sovereign' has been generalized into uselessness by 2026 marketing. Six concrete tests separate sovereign from sovereign-flavored, with worked examples from the operating log of a stack that just moved from 5/6 to 6/6 on the framework below.

Backing Up 119B Parameters Without Going Bankrupt on Storage
Backing up model weights is the wrong abstraction. Backing up the model identifier, the configuration, the customer data, and the runbook is the right one. The weights are reproducible; the data and the runbook are not.

DGX Spark vs Apple Mac Studio: Which Wins for Local LLMs?
The Spark wins on MoE-class language models and the developer-tooling pipeline. The Mac Studio wins on silence, daily-driver ergonomics, and memory ceiling (up to 512 GB on M3 Ultra). The choice depends on which column is binding for your workload.

Five DGX Spark Disasters I Survived (You Don't Have To)
Five operational failures from the first two months on a Spark, with the actual fixes and the postmortem links. The pattern is the same: a quiet default value, a non-obvious failure mode, several hours of confused debugging, then a one-line workaround that should have been in the documentation.

Mistral Small 4 vs Qwen 3.6 vs GLM-5.1 on a Single DGX Spark
Three production-class open-weights models, all weighed against one Spark. Qwen wins on coding throughput and now sustains around 71 tok/s under DFlash. Mistral holds the creative-prose and verified-vision slot as a safer fallback. GLM-5.1 at 754B does not fit and the reason it does not fit is the most useful lesson in this comparison.

Should You Buy a DGX Spark in 2026? The Honest Decision Tree
About a third of the people who ask me end up not buying. Six specific 'don't buy' clauses, four buyer profiles, the four real alternatives ranked, a flowchart, and the operational receipts (drop_caches=3, VLLM_FLASHINFER_MOE_BACKEND=latency, 30-minute recovery runbook) the spec sheet does not give you. Lead-magnet source; also gated as PDF.
5 MCP Patterns That Aren't 'Search the Database'
Every MCP server tutorial demos search. The five patterns below are the ones that actually justify the protocol on the second day after you launch: structured-write, status-with-history, batched-action, paid-action, capability-discovery. Each has a worked example.

Astro 6 + Caddy: The Static-First AI Blog Stack
Static site generation, no database, no PHP, no CMS. The blog is markdown files in a Git repository, built locally, rsynced to a small VPS, served by Caddy. Faster than any WordPress, immune to the WordPress vulnerability class, and the archive is plain text on disk.

MCP for Engineers Who Hate Marketing: A 6-Week Build Log
Six weeks from 'I should publish an MCP server' to 'the server is live, registered, scored 100/100 on Smithery, and listed in three directories.' The log is week-by-week, with the actual command lines and the actual mistakes.

NVIDIA Playbooks: Where They Help and Where They Don't
NVIDIA's published reference playbooks are excellent for the workflows they cover and quietly misleading for the workflows they do not. Three categories of help, three categories of trap, and the rule for telling them apart before you copy a configuration into production.

Coding Assistants on a Sovereign Stack: Claude Code, opencode, Aider, OpenClaw (and why Vibe got retired)
Four assistants still on the table in 2026 plus one I uninstalled. Claude Code wins on raw capability, Aider wins on git discipline, opencode is now the local primary against Qwen 3.6, OpenClaw stays as the Mistral specialty. Vibe is in the postmortem column.

Caddy + Cloudflare Tunnel: The Reliability Pattern
Caddy on a small VPS, Cloudflare Tunnel to the home Spark, no inbound ports open at the residential ISP. Six hundred milliseconds of TLS handshake handled by a CDN that can absorb the abuse the operator cannot. The honest rented dimension and the migration path if it has to come back.

Hardware Wallet Integration for Self-Hosted Lightning
The hardware wallet holds the seed; the node holds the channel keys. The integration pattern is straightforward in principle and finicky in detail. Here is the working setup with the BitBox and the LND backend, plus the three integration mistakes I made before it worked.

The Operator's Guide to Self-Hosted Lightning
Lightning is the sovereign payment surface. Running your own node is the difference between accepting Lightning and being Lightning. Here is the working setup, the operational discipline, and the failure modes that bit me in the first two months.

Tailscale vs Headscale for Multi-Box Sovereign Stacks
Tailscale is the right pick if your sovereignty budget is finite and the rented coordination server is an acceptable trade. Headscale is the right pick if the coordination server's vendor risk is the dimension you cannot accept. Both ship the same WireGuard underneath.

Tor Hidden Service for Sovereign AI: When and How
A Tor hidden service in front of a sovereign-AI endpoint is the right answer for three specific reader populations and the wrong answer for everyone else. Here is how to tell which population you are in, and the configuration if you are.

AIDE + Tripwire for AI Boxes: When File Integrity Matters
File-integrity monitoring is unnecessary on most workstations and necessary on a few specific ones. The AI box that runs other people's inference is squarely in the necessary category. Here is how to wire AIDE and Tripwire without producing alert fatigue.

Gitea as Source-of-Truth for AI Pipelines
A self-hosted Gitea instance holds the prompts, the unit files, the runbooks, the customer data references, and the model identifiers for the sovgrid AI stack. The pattern is mundane and load-bearing.

Power Failure Recovery on a DGX Spark: The 30-Minute Procedure
A step-by-step runbook for getting a DGX Spark back to full production after a power event. Thirty minutes if you have rehearsed; two to six hours if you have not. The procedure assumes a UPS for graceful shutdown and a separate management host.

Self-Hosted Observability for a One-Person AI Stack
Prometheus plus Grafana plus one phone number plus the discipline to never alert on something that is not actionable. The observability stack that lets one operator sleep through the night and still catch the failures that matter.

I Built a Web UI for Mobile Coding. Termux Won Anyway.
Two days of reverse-proxy work, a full Caddy stack with Let's Encrypt TLS and basic-auth in front of opencode web, all working. Then I realized I am not the right user for it. The actual mobile answer was already on my phone, and OpenWebUI quietly took over the other half of the use case.

systemd Patterns for Self-Hosted AI Services
Six unit-file patterns that make a multi-service AI stack survive crashes, reboots, and power events without operator intervention. The patterns are not novel; the discipline of applying them consistently is.

Three Coding Leaderboards, Three Blind Spots: What HackerNoon and WhatLLM Don't Tell Self-Hosters
HackerNoon ranks coding LLMs by programming language. WhatLLM.org aggregates LiveCodeBench, Terminal-Bench and SciCode. Neither tests self-hosted models on real hardware. A self-hoster's reading protocol for coding leaderboards.

What Goes Wrong at Token 4096: A Context-Window Failure Atlas
Eight specific failure modes that surface as the context window fills. They are not the same failure mode; the fixes are different. The atlas helps you tell which failure you are looking at when the agent starts producing garbage.

EAGLE Speculative Decoding: When It Helps and When It Doesn't
EAGLE accelerates conversational and long-prose workloads by 2-3x on Mistral Small 4. On structured-JSON output, the same configuration is net-negative. The decision rule is the workload class, not the inference engine.

NVFP4 Quantization Explained (For Engineers Who Skipped the Paper)
NVFP4 is a 4-bit floating-point format with a tiny exponent field, designed for inference-time activation and weight quantization on Blackwell-class hardware. Here is what the format actually does, why it is faster than INT4 on Spark for some workloads, and where it loses to other quantization choices.

The Unified-Memory Inference Mental Model
Unified memory is not a bigger pile of RAM. It is a different architecture, and the mental model for what makes inference fast on it is different from the model for discrete-GPU inference. Here is the working model after two months on a DGX Spark.

FIPS, the Mesh Protocol, and Why I Need to Build It to Believe It
The planning post before the implementation post. FIPS is an open-source mesh protocol with cryptographic identity and transport-agnostic routing. My sovereign AI stack is sovereign at the model and the hardware, and leaks the whole workload at the network boundary. Here is why that gap matters, the five concrete pieces of work I am committing to, and why I write the plan in public before I know if it works.

Bitcoin Connect: window.webln Stays After Disconnect
A defensive PR review exposed a 2-year-old WebLN provider leak in Bitcoin Connect's recommended pattern. The fix is three lines in the README. PR #385 merged 2026-05-07.

EAGLE Throughput Is Content-Dependent: Same Run, 14 to 31 Tokens Per Second
I added a numerical output contract to my Mistral prompt and watched throughput drop in half on the same hardware. Then the naturalize step in the same pipeline run hit 31 tok/s. Live SGLang logs explain why, and what to do about it.

Per-Segment Loudnorm and the 3-Second Lookahead Bug
Per-block ffmpeg loudnorm averages multiple speakers to one gain, leaving the quieter voice quieter. Dynamic-mode loudnorm eats the first 3 seconds of audio.

Why SGLang Never Froze My Desktop But vLLM Did: an SM 12.1 MoE-Kernel Story
A vLLM-Qwen container ran four days clean, then froze the whole GNOME desktop the moment any GPU app opened. SGLang-Mistral never did this in days of uptime. The cause: vLLM's FlashInfer MoE throughput backend has broken SM120 kernels on the DGX Spark's SM 12.1 GPU, and on unified memory a bad kernel launch takes the display down with it. One env var fixes it.

Mistral vs Qwen3.6 on DGX Spark: the 0/30 That Was a Broken Ruler
I almost published 'Mistral Small 4 scores 0/30 on coding, the quant kills it'. A competent model scoring exactly zero should have been the red flag. The benchmark harness was hanging behind this stack's Tor docker proxy and never reached the model. Here is the broken-ruler story, the direct measurement that replaced it, and every Mistral-vs-Qwen3.6 number at a glance, including which one can actually read an image.

The Quality Gate That Rewards Fabrication: I Had Qwen and Mistral Write This Blog
This blog gates every article behind one Python scorer before it publishes. I gave Qwen3.6 and Mistral Small 4 the same brief, the Start Here hub article this site still owes, and ran the raw output through that real gate with no editing. Both passed. Both invented hardware, processes, and benchmarks the scorer counted as quality. Here is the full method, the two source texts, and why a passing score is a floor and not a truth filter.

The Quiet Pattern Among Sovereign Engineers
Six traits I keep seeing across the people who fit the sovereign-engineer description: they argue with specs, name every dependency, default to publishing, plan in decade arcs while shipping weekly, price friction honestly, and gate their optimism. Written from the outside, by the operator who runs the iron the sovereign software eventually touches.

Why hf download Lies to You at 22 GB on DGX Spark
The huggingface-hub CLI exits zero while leaving five out of six safetensor shards as .incomplete files. Three failure modes from the same model pull, and the wrapper that catches all of them.

opencode Setup: Self-Hosted AI Coding Assistant on ARM64
Replace cloud AI coding assistants with opencode, a provider-agnostic Node CLI plus Electron desktop app. Points at any OpenAI-compatible endpoint, ships in three frontends. Includes the 2026-05-13 correction on the auto-title-generator Mistral BadRequest gotcha and the JSON-config-only setup syntax.

TTS Spike Day 1: VibeVoice Sample Matrix on DGX Spark
Eleven VibeVoice renders, one Voxtral baseline, the operator's ears. The first day of the TTS spike that follows the V6=0/10 verdict. Engineering-log shape, with the actual audio embedded. Day 2 went to a late entrant, Qwen3-TTS.

How to Auto-Post on Nostr Without Reading Like a Bot
Five posts a week, no marketing department, no template-substitution. Building a Nostr distribution cadence for a self-hosted blog that does not embody what readers can spot in two scrolls.

Voxtral Capped at 3/10: Picking the Next Open TTS
Eight engineering fixes deep, three weeks of patches, two failure modes on the same engine. The Voxtral open checkpoint has no path to release-quality podcast audio. The drama of staying with it anyway, and the three engines I plan to spike next.

Three Self-Healing Patches in One Day, All the Same Shape
Three pipeline gaps surfaced in a single afternoon. Each was silent for weeks. The same three-part pattern fixed all of them. Concrete code, before-and-after numbers, and the discipline that keeps it from happening again.

Why 334 Unique IPs Was Really 5 Services in Trench Coats
My MCP-server NSM page showed 334 unique agents. One change to the aggregator (User-Agent plus IP /24 dedupe) and the truth surfaced: 86% of external hits come from a single /24 range, the rest are mostly automated probes. Headline metrics that look like reach can be five services pretending to be many.

How to Read the Insights Dashboard for a DGX-Spark Business, Not a Hobby Blog
Each number on the live Insights page has a formula, a business meaning, and a vanity-trap. If you are running a DGX Spark as the engine of a small AI service, here is how to read the dashboard daily without chasing growth-theatre, and which two metrics are the only ones worth waking up to check.

Spark Arena Rank 4 Made Me Add Qwen3.6 to My DGX Spark
Qwen3.6-35B-A3B PrismaQuant at 95 tok/s on a single Spark (Spark Arena rank 4) beats my measured Mistral Small 4 at 35 tok/s by 2.7x on paper. This is the plan, not the result. SWE-Bench scores, opencode replacing vibe, why Mistral stays installed for creative prose, the Hacker News critiques on opencode I take seriously, and the two-day prep before day-2 measurements land on 2026-05-25.

FFmpeg Volume Filter eval=frame: A 4-Second Silent Bug
The intro music wasn't playing for the first four seconds of every podcast episode. RMS at minus infinity. The fix was one keyword, eval=frame.

Voxtral 4B Open-Checkpoint: The Encoder is Gated
Voxtral 4B advertises voice cloning, accepts ref_audio in the API, then crashes the engine because the encoder weights live only in Mistral's hosted product.

Voxtral Chunk Strategy: 38 Percent Faster Render with Whole Turns
Rendering a 367-character podcast turn as one Voxtral call takes 21 seconds. Split into 90-character chunks: 35 seconds. Same words, same voice, 38 percent more wallclock.

My Backup Ran for Six Weeks Without Backing Anything Up
Green systemd timer, healthy logs, four silent bugs. The backup script never executed once. Here is the postmortem and the rebuilt three-tier architecture that replaced it.

I Gave My Blog a Search Box, and It Runs Through My Own MCP Server
Wired a browser search form directly into an MCP tool that AI agents already call. One afternoon, four endpoints, zero CORS, real numbers from the deploy. The mistakes that cost me an hour are documented inline.

Alby Hub on ARM64: Self-Hosted Lightning Node in Docker for DGX Spark and Other ARM Boxes
Run your own Lightning node on an ARM64 Linux box. Five-minute Docker setup, channel opening, sub-wallets via NWC, and the gotchas that x86-only guides skip.

How Much Electricity Does Self-Hosted AI Actually Use? Lightbulbs, Bitcoin Miners, and Solar Panels
What a DGX Spark actually draws from the wall, what that costs in Germany versus the US, how it compares to a lightbulb and a Bitcoin miner, and how many solar panels would offset it. With sources.

Voxtral Podcast Audio: Mono 24 kHz Baseline and Three Compression Pitfalls
How we fixed loudness pumping, markup stripping, and dialogue rhythm in a self-hosted podcast pipeline

Voxtral-TTS Blocker on GB10: The Three-Line vllm-omni Patch
How a silent AttributeError nearly killed our TTS pipeline, and why three lines of code fixed it forever.

The 3.5-Hour Deadlock That Was Really an AttributeError
How a three-line Python init order bug masqueraded as a Blackwell GPU hang, and why checking raw logs beat all hardware theories.

Sovereign Grid Dashboard: Architecture, Service Tab Overhaul, and Service Control Pattern
A deep dive into a self-hosted AI operations dashboard that replaces cloud dashboards with a privacy-first, hardware-aware control plane. Learn how the Service tab was rebuilt to handle long commands without layout breaks, how service control works at the system level, and why a single source of truth for your AI stack matters.

The Sovereign AI Blog MCP Is Mostly Redundant Today, And That Will Change
Why the first Sovereign AI MCP server isn't worth installing yet, but will be once it hits 200 articles and adds specialized tools. An honest MVP/POC critique.

Floki-VPS Setup for Sovereign AI Workloads
Move your AI stack off cloud servers. This post shows how to migrate a production Sovereign AI blog and MCP server to a €163/year VPS, harden it, and run it with Docker and Caddy, complete with real configs and pitfalls.

Build a Self-Hosted Knowledge Base with Plain Text and LLMs
A practical guide to setting up a searchable, growing knowledge base using Markdown files, JSON indexing, and local LLMs, no vector stores required.

OpenClaw Setup on DGX Spark for Sovereign AI Agents
A hands-on guide to installing and configuring OpenClaw on NVIDIA DGX Spark, switching between cloud and local models, and wiring MCP servers.

Sovereign MCP Server: Local Setup, Integration, and Hard Lessons
Learn how to run a self-hosted MCP server for your blog’s knowledge base, integrate it with OpenClaw and Vibe, and avoid the pitfalls I hit while migrating from cloud to Sovereign AI.

How Two Sovereign AI Personas Run Your Blog and Nostr Feed
Cipherfox and Hexabella post curated content without human oversight, using Mistral Small 4 on a DGX Spark and a hardened signing service. Here’s how it works today.

Hub Articles Protocol: How Three Reading-Paths Earn Their Homepage Slot
How sovgrid.org structures its most important posts to guide readers and shape the blog’s identity.

MCP Registry Distribution: Submission Plan & Tracking
How we’re getting the Sovereign AI MCP endpoint listed in five registries with real traffic tracking and zero KYC friction.

OpenClaw: What’s Still Missing for Full Usability
A no-BS breakdown of the gaps in a self-hosted AI stack and the exact next steps to plug them.

Building Per-Article Zap Tracking on Nostr, and Then Getting Zero Zaps
Three Nostr identities, a working zap-attribution pipeline, 44 articles live at the time of writing, and after 30 days exactly zero zaps. What I learned about V4V on a small technical blog.
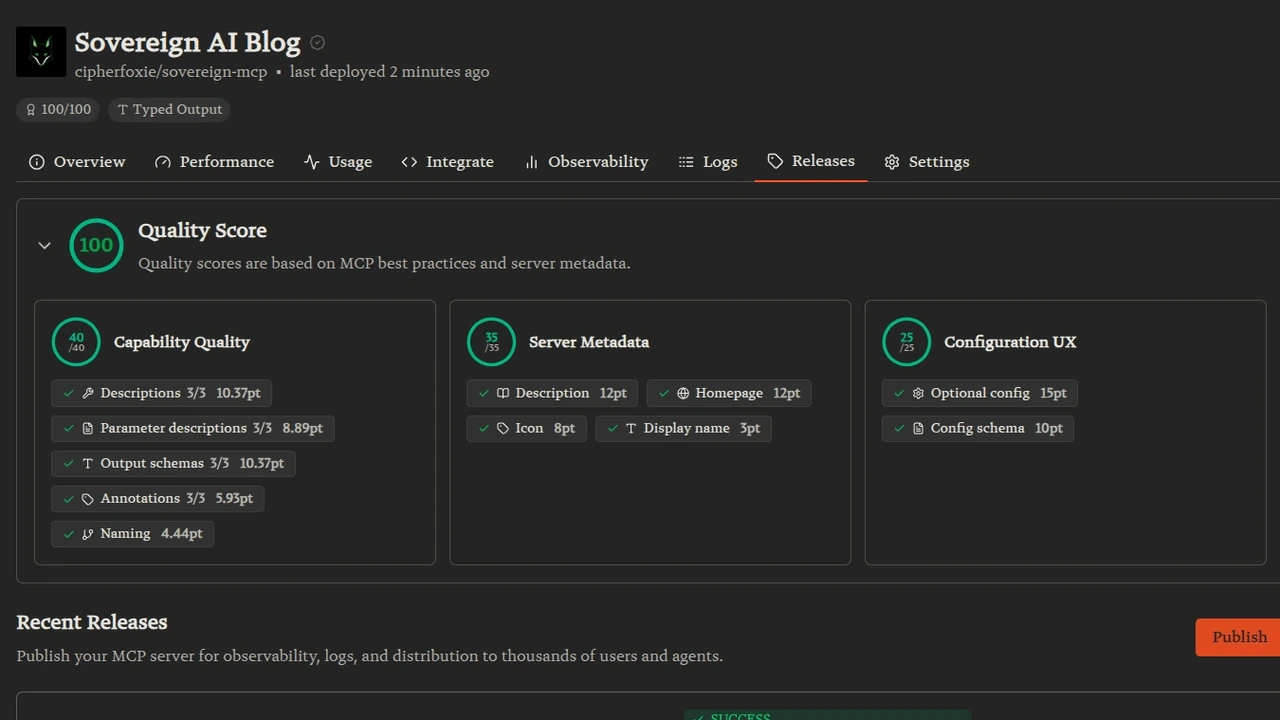
100/100 on Smithery in 4 Hours, and Why That Means Almost Nothing
Built a self-hosted MCP, mirrored it to GitHub, listed it on Smithery, hit a perfect quality score before dinner. The exact patches, badges, and pitfalls. Plus an honest take on why a number on a dashboard is not a customer.

Two Days From Localhost to Production: Building a Hybrid Sovereign AI Site
A two-day build log from localhost to a sovereign hybrid AI site. Three failure modes, exact fixes, and the reproducibility checklist most cloud guides skip.

Two Leaderboards Nobody Reads Together: Why arena.ai Doesn't Tell You About Self-Hosted AI
Mainstream AI coverage cites only one leaderboard. arena.ai ranks quality. spark-arena.com ranks throughput on real hardware. The decision that matters lives in the third column nobody publishes.

Sovereign AI Grid: What's Working and What Comes Next
Status snapshot of what is running on this stack today and what is being built next. For returning readers. New here? Read 'Self-Hosted AI: Start Here' first.

Fix OpenClaw + SGLang with Mistral: Stop the "conversation roles must alternate" 400 BadRequest
Learn how a 200-line proxy fixed a strict role-alternation bug that broke Mistral Small 4 after the first few turns

A Self-Hosted AI Blog That Serves Both Humans and Machines
This technical blog maintains a single source of truth while layering machine-readable tools on top, ensuring both human readers and AI agents get accurate, up-to-date information.

From Blog to Agent Tools: How One Knowledge Base Powers Both Humans and AI
Learn how to transform your technical blog into a dual-purpose knowledge base that serves both human readers and AI agents while future-proofing your content strategy.

Voxtral Stage 1 OOM on GB10: Why --enforce-eager Is Not Enough
How a single flag killed my self-hosted TTS stack, and how I fixed it without losing a second of audio.

Running a 119B AI Model at Home: Who Actually Does This in 2026
A deep dive into the DGX Spark ecosystem, real power costs, and agent-driven tool adoption for self-hosting 119B models at home in 2026.

Hands-on AI Coding Tools: Why I Kept Claude Code + Vibe and Dumped Cursor and Continue.dev
A hands-on comparison of AI coding tools testing local inference vs cloud dependency for privacy-first workflows.

Six Weeks Running Mistral Small 4 as a Production Tool: What I Actually Learned
A deep dive into optimizing Mistral Small 4 for local technical blogging, with practical solutions for session memory, image generation, and EEAT compliance.

Content Quality in the AI Age: Where Our Scoring System Is Right, Wrong, and Missing
A full-system review of our quality scoring pipeline against a rigorous philosophical framework. Three things it confirms, two things it exposes, and one concrete fix that changes the architecture.

Build a Self-Hosted AI Blog with Astro, Mistral, and ComfyUI on One Machine
A practical guide to running a full content pipeline, writing, generating images, and serving, on your own hardware with Astro, Mistral Small 4, and ComfyUI FLUX.

Sovereign Blog Setup: Self-Hosted AI Content Pipeline & Monetization
A hands-on guide to deploying a self-hosted AI blog with Docker, Astro, and MCP discovery, complete with working code, real-world gotchas, and monetization via Lightning and Nostr.

Self-Host Mistral Small 4 with SGLang on NVIDIA DGX Spark (GB10): What Actually Works
Run Mistral Small 4 119B on NVIDIA GB10 with SGLang nightly: exact flags, real benchmarks, every gotcha that costs a day

ComfyUI plus FLUX.1-schnell on DGX Spark: Per-Style Visual Vocabularies
Optimized workflow for running FLUX.1-schnell and Mistral sequentially on NVIDIA DGX Spark with 128GB unified memory

Self-Hosted AI Pipeline (Part 1): Targeted Scripts, Hardware-Crashing Flags, and Why Grep Beats LLM
A practical guide to optimizing a self-hosted AI content pipeline with targeted scripts, grep-based validation, and precise flag handling.

Self-Hosted AI Content Pipeline: What Works and What Doesn’t
Lessons learned from a failed LLM self-review experiment that broke our validation pipeline and how we fixed it with deterministic checks.

Automate Better Blog Posts: Self-Hosted Article Optimization That Actually Works
A weekly automation pipeline that repairs, updates, and optimizes self-hosted blog articles in place using Mistral and SearXNG.

How Four Silent Failures Made My Backup System a Security Theater
A senior engineer walks through the four hidden failures that made his backup system look healthy while actually failing for six weeks. Includes the exact commands, error messages, and hardware specs that turned a disaster into a reliable setup.

Feedbin and Lightning V4V: Tipping RSS Authors Through Alby
Learn how to implement Value-4-Value payments in Feedbin using podcast:value tags and the Alby bounty for a zap button.

Gitea ARM64 Setup: Tor Hidden Service and Sovereign Dev Workflow
A detailed guide to deploying Gitea on ARM64 with Docker, SQLite, Tor access, and automated encrypted backups.

OpenHands Setup with Mistral-via-SGLang: The Multi-Arch Container Recipe
Deploy a privacy-respecting AI coding assistant with Mistral Small 4 and SearXNG using Docker on ARM64 hardware.

Android AI Terminal: SSH plus Termux plus tmux for the AI Stack from Your Phone
Turn your Android device into a full terminal for your Sovereign AI Grid with Termux, Tailscale, and tmux for seamless remote access.

Alby Lightning Wallet: From Zero to Sovereign AI Tipper in 30 Minutes
Learn how to install Alby, receive your first Lightning payment, and become a Nostr power user with Zaps, all without trusting a bank or exchange.
Alby + Nostr: Send Lightning Zaps with Sovereign Identity
Skip the cloud accounts. Use Alby’s NIP-07 signer to send Bitcoin zaps directly from your browser, no middlemen, no passwords, just your keypair and a Lightning wallet.

BitBox02: The Swiss-Made Hardware Wallet for Sovereign Bitcoin
Why Swiss precision matters for your Bitcoin self-custody stack: and how to set it up in under 30 minutes without trusting anyone

Sovereign AI Webshop (Part 1): No-KYC Lightning Checkout Architecture
Deploy a self-hosted WooCommerce stack with one command, full privacy control, and ARM64 support from Raspberry Pi 5 to DGX Spark.

Sovereign Webshop Setup
Optimize your cloud costs, secure your login pages, and activate Amazon Associates with this battle-tested webshop setup guide.

Privacy-Hardened AI Stack: OpenHands, Aider, and Gitea over Tor
A hardened local AI development stack using OpenHands, Aider, and Gitea over Tor with Mistral Small 4 inference

SOVEREIGN DEV STUDIO v2: Self-Hosted AI Coding Agents That Actually Work
How to run OpenHands and Aider locally with Mistral Small 4 and Qwen3 Coder Next for reliable, private AI-assisted development.

Sovereign Dev Stack: Gitea-as-Tor-Hidden-Service and pip-via-Tor
Protect your code and metadata from cloud services using self-hosted Git, Tor routing, and privacy-focused package management.

How to Bootstrap New Sovereign AI Projects with SHARED_CORE
Learn how SHARED_CORE enforces security and consistency across Sovereign AI projects while automating setup with standardized scaffolding.

Docker Dev Stack on DGX Spark: Compose Patterns for Sovereign AI
A practical guide to configuring a secure, self-hosted Docker development stack with OpenHands, Gitea, and model caching for Sovereign AI.

NVIDIA Playbook Stack
How NVIDIA's tested playbooks transform DGX Spark into a reproducible AI development environment with pre-configured stacks, MCP integration, and battle-tested configurations.

Aider Setup on DGX Spark: Mistral-via-SGLang Endpoint and Tor-Routed pip
Learn how to install and configure Aider for reliable local LLM coding sessions on ARM64 workstations with practical troubleshooting tips.

Three Silent Failures That Would Have Killed My Self-Hosted AI Stack
How a single SSH syntax error, misconfigured swappiness, and container limits almost took down my Sovereign AI stack, and the exact commands I used to fix them.

Cloudflared in Astro's Docker Network: The Hostname-Resolution Fix
Resolving Docker network isolation between cloudflared and an Astro static site container to restore Cloudflare Zero Trust tunnel functionality.

Reclaiming 20 GB: Dead Docker Images and Why Caddy Runs Better as systemd
Learn how to reclaim disk space from unused Docker images and optimize your stack by running Caddy as a systemd service instead of in Docker.

OpenHands and Gitea Integration: Docker-Network Hostname Fix
Resolve Docker networking failures where containers can't resolve names or access volumes, with a single `.gitconfig` tweak that fixes both issues.

Fix: OpenHands BadRequestError: Mistral Alternating Roles
OpenHands crashes after 10 minutes with a BadRequestError. Here’s exactly how to fix the alternating roles bug in Mistral Small 4 and why the default config is broken.

OpenWebUI Port Conflict on DGX Spark: Why 8080 Was Already Taken
Learn how to diagnose and resolve Docker port conflicts with practical troubleshooting steps and configuration fixes.

Vibe 400 Bad Request Fix: Mistral Alternating Roles and reasoning_effort
Three separate 400 Bad Request causes in Mistral Vibe with SGLang, their root causes, and update-safe fixes

Vibe write_file Overwrite Bug: When Edits Silently Replace Whole Files
How strict workflow rules and tool constraints prevent AI agents from destroying your codebase during file edits.

SGLang Restart OOM Fix: Unified Memory Cleanup on GB10/DGX Spark
How I wasted three days debugging SIGKILL 137 after every SGLang restart, until I learned that GPU memory isn’t freed instantly and Docker’s `--rm` and `--restart` hate each other.

SGLang on DGX Spark: 35-41 tok/s with EAGLE Speculative Decoding
How we got Mistral Small 4 119B inference working on NVIDIA DGX Spark's ARM64 GB10 chip with SGLang, including backend selection, speculative decoding, and Vibe CLI optimizations.

Four Bugs That Only Showed Up Under Load: Fixing a FastAPI Dashboard
Async event loop blocking, N+1 Docker calls, systemd ProtectSystem conflicts, and stacking frontend polling: four independent bugs in one FastAPI app, all invisible at idle.