100/100 on Smithery in 4 Hours, and Why That Means Almost Nothing
New to self-hosting AI? The Self-Hosted AI: Start Here hub walks the hardware-decision tree, inference-engine choice, and the operational gotchas that bite hardest in the first three months. Read it before or after this one, whichever fits your stage.
Update 2026-05-03: Frank cleared the Glama namespace conflict the same evening this was first drafted. Connector path live at
glama.ai/mcp/connectors/org.sovgrid.mcp/sovereign-ai-blog. Server path live atglama.ai/mcp/servers/cipherfoxie/sovereign-mcpwith a working badge URL. The awesome-mcp PR (#5645) merged on 2026-05-02, a Saturday, without further intervention. Three directories live, zero MCP tool calls so far. The “currently on hold” and “waiting on Frank” passages further down stay as the working-log they were. The closing section still applies.
The first Smithery score was 78. Five hours later it was 100. The MCP server was not really better at what it does. It just stopped lying about itself.
This post is the working log of that afternoon: what got submitted, what scored, what failed verification on the first try, and the exact code patches that closed the gap. It is also a reminder, mostly to me, that a perfect score on a directory dashboard is not the same as a single agent actually using your server. The day NSM ticks past zero is the day the work paid off. The day you hit 100 on the score is the day you finished the homework.
On this page:
- What got listed
- The directories want you
- Server path or Connector path
- The 78/100 breakdown
- The Pydantic refactor
- Verification with the MCP Inspector
- The three verification gates
- What broke and what almost broke
- Things attempted today that did not make this article
- Lessons
- Why this is not a breakthrough
- Glama, less easily impressed
- Try it
- Stack and disclosures
The afternoon almost ended at 16:30 with a different blog post. Title: Why sovgrid.org/agents Looks Broken in Tor Browser And I Cannot Tell You The Fix. I burned ninety minutes on responsive CSS in Tor’s resistFingerprinting mode, redeployed seven times, never saw the page on a real phone, eventually deleted the light-mode override outright and called it design discipline. The post you are reading is the one with verifiable artifacts. The other one is on the TODO. Future cipherfox will read that title in 2028 and remember exactly which afternoon it was, and exactly which key combination did not exist on the Spark keyboard at the time.
What got listed
The server lives at https://mcp.sovgrid.org/self-hosted-ai. It exposes four tools to AI agents:
search_blog(query, tag?, sort?, n?): TF-IDF over title, description, tags, and the first 500 chars of body across 44 articles. Optionaltagfilter, sort by relevance or date.list_tags(sort?): Returns every topic tag in the corpus with article counts. Use to discover the topic space before filteringsearch_blog. (Added after the original Smithery push: gap-detected by Glama’s quality bot, shipped same week.)get_article(slug): Full article content by slug, returns Markdown plus metadata.diagnose_sglang(error_message): Pure pattern matching against documented GB10/SM121A failure modes, returns critical issues, warnings, and a known-good baseline config.
The corpus is this blog. Hands-on engineering notes for self-hosted AI on NVIDIA DGX Spark hardware. Training data on niche stacks like SM121A is sparse and stale. An MCP that exposes verified, dated documentation directly to agents is a small lever with outsized impact: agents stop hallucinating flag combinations and start answering with prior art that has actually been run.
Stack:
- Python 3.12 with FastMCP 1.27.0
- Streamable HTTP transport at
/self-hosted-ai - Caddy reverse proxy with TLS
- Hosted on a privacy-focused European VPS
Source: github.com/cipherfoxie/sovereign-mcp, MIT-licensed. The full FastMCP entrypoint is src/main.py.
The directories want you, but only on their terms
Three places matter for MCP discovery right now:
- Smithery, a marketplace with a quality score and a Streamable-HTTP gateway.
- Glama, a directory plus chat playground. Has both a Server path (Dockerfile) and a Connector path (hosted endpoint).
- punkpeye/awesome-mcp-servers, a community list with 86k stars and a PR bot that requires a Glama listing first.
MCP-Get was a fourth, but the project archived itself. The directory is read-only. RIP.
The submission mechanics differ. Smithery and Glama are both Web forms with email or GitHub OAuth. The community list is a GitHub PR. None can be fully automated by a CLI tool unless you already control the GitHub account, which is to say: a human still presses go on each one. That is fine, the work is in the artifacts the directories then read, not the click.
Server path or Connector path
Smithery’s submission flow gave the first decision. Server path expects a Dockerfile and clones from GitHub. Connector path expects a deployed URL. For a server that already runs in production, Connector is the correct choice. Server path verification builds the image on Smithery’s infrastructure and answers introspection from there, which only makes sense for code that users will run themselves.
The Connector form asked for:
- Display name:
Sovereign AI Blog - Endpoint URL:
https://mcp.sovgrid.org/self-hosted-ai?ref=smithery - Homepage:
https://sovgrid.org/agents/ - GitHub repo:
https://github.com/cipherfoxie/sovereign-mcp
The ?ref=smithery query parameter is for attribution. The MCP server ignores unknown query strings (FastMCP routes on path), but Caddy logs them. A nightly aggregator script extracts each ref value and counts tool calls per registry, so the contribution of each listing is visible without any client-side tracking.
After submission, Smithery introspected the server and pulled the metadata. Tools list arrived clean. Quality score: 78/100.
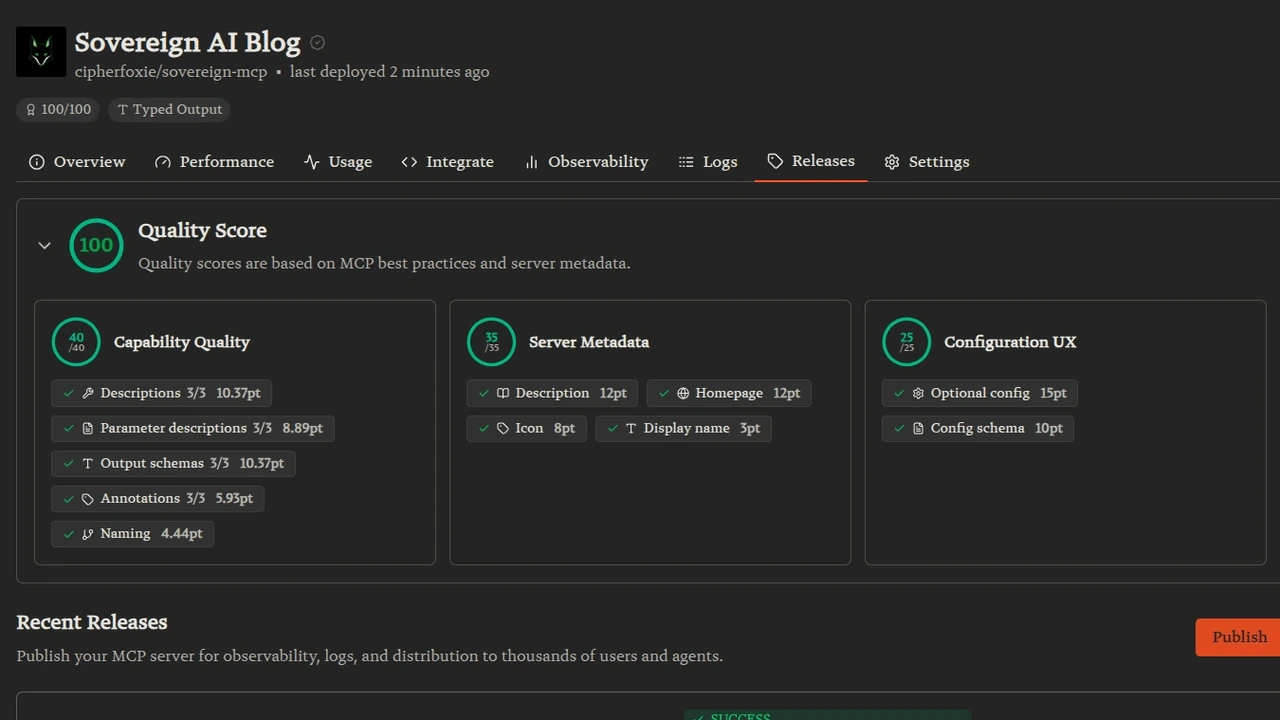
The 78/100 breakdown
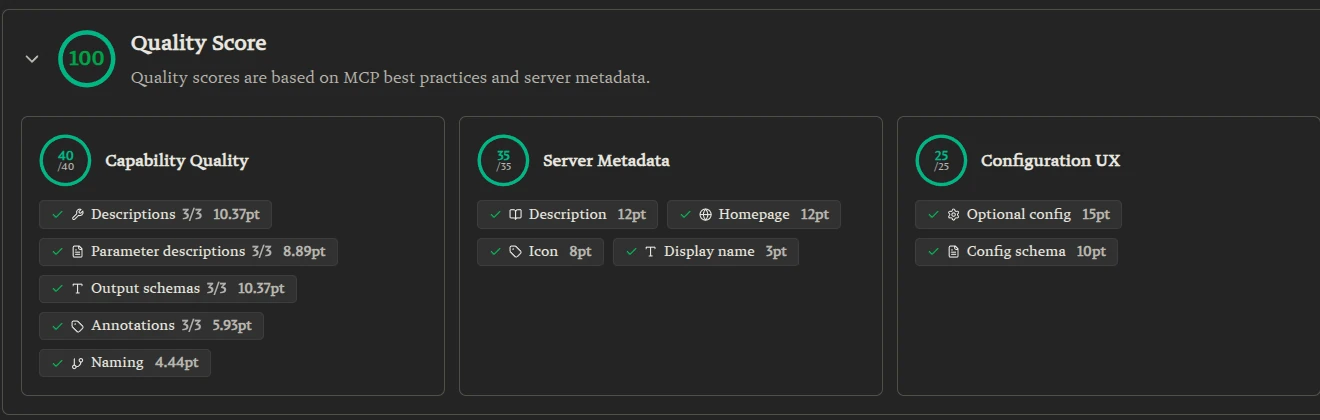
Three sections, three numbers:
- Capability Quality 18/40. Descriptions and Naming were green. Parameter descriptions 0/3, Output schemas 1/3, Annotations 0/3 were all red. Worth roughly 25 points combined.
- Server Metadata 35/35. Display name, description, homepage, icon: green from the start.
- Configuration UX 25/25. Optional config and config schema: green from the start.
The metadata and config sections passed because they were filled out at submission time. The capability gap was a code problem.
Smithery does not extract parameter or return descriptions from Python docstrings. Read that twice, because it is the entire trick. Smithery reads the JSON Schema that FastMCP builds from the type hints. If the type hint is query: str and the docstring says “Args: query: a search query”, Smithery sees str with no description. The score lands on 0 for parameter description.
Same for output. A -> dict return type yields a vacuous schema. Smithery scores 0 on output schema.
Tool annotations are the four standard MCP signals (read-only, idempotent, destructive, open-world). FastMCP only emits them when explicitly passed.
All three are populated through one mechanism. Pydantic.
The Pydantic refactor
The fix on search_blog: switch every parameter to Annotated[type, Field(description=...)] and return a typed Pydantic model.
from typing import Annotated
from pydantic import BaseModel, Field
class SearchResult(BaseModel):
"""One ranked article result from search_blog."""
slug: str = Field(description="Article slug, use as input to get_article")
title: str = Field(description="Article title")
url: str = Field(description="Public URL of the article")
description: str = Field(description="Article description or summary")
tags: list[str] = Field(description="Topic tags assigned to the article")
relevance_score: float = Field(description="TF-IDF cosine similarity, 0 to 1")
quality_score: float = Field(description="Build-time editorial quality score")
quality_style: str = Field(default="", description="Editorial style category")
def search_blog(
query: Annotated[str, Field(description=(
"Natural language search query (e.g. 'flashinfer OOM on GB10'). "
"Multi-word queries are tokenized and TF-IDF ranked."
))],
n: Annotated[int, Field(
description="Maximum number of results to return", ge=1, le=10,
)] = 5,
) -> list[SearchResult]:
"""
Search the Sovereign AI Blog for articles matching a natural language query.
Pure read-only, deterministic for a given KB snapshot.
"""
...Annotated[str, Field(description=...)] is what FastMCP picks up for the parameters JSON Schema. Plain docstrings are ignored. The ge and le constraints become minimum and maximum in the schema. Smithery picks both up.
The return type list[SearchResult], where SearchResult is a BaseModel, gives FastMCP a real output schema instead of array of dict. Smithery scores +10.37 on Output Schemas the moment the server restarts.
For tool annotations, the import comes from mcp.types:
from mcp.types import ToolAnnotations
mcp.tool(annotations=ToolAnnotations(
title="Search Blog",
readOnlyHint=True,
idempotentHint=True,
openWorldHint=False,
))(search_blog)readOnlyHint=True advertises that the tool does not mutate state. idempotentHint=True means the same input gives the same output, agents can retry safely. openWorldHint=False declares that the tool only reads a closed local KB and does not make external calls. All three signals reach Smithery and any compliant client.
Same pattern for get_article and diagnose_sglang. The diagnose tool is the most useful demonstration: six optional parameters, each with a description that tells the agent what to fill in, and a typed DiagnoseResult return with sub-models for DiagnosticIssue and RecommendedConfig.
Verification with the MCP Inspector
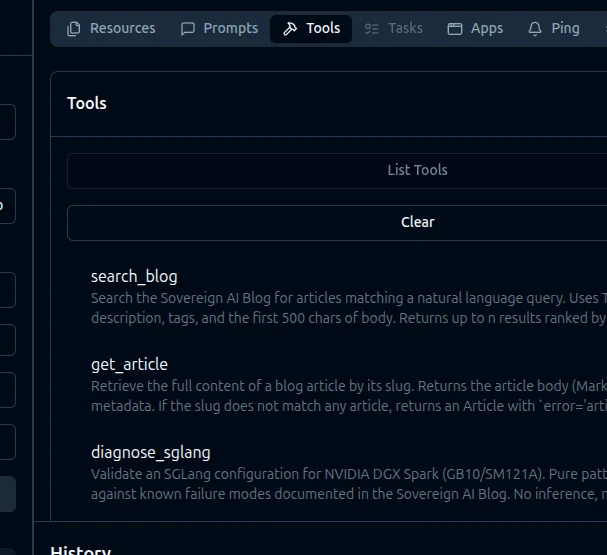
Smithery’s score is a number on a dashboard. To check that the underlying schemas are real, the MCP Inspector renders the server exactly the way Smithery and any other compliant client does.
npx @modelcontextprotocol/inspectorConnect via Streamable HTTP to https://mcp.sovgrid.org/self-hosted-ai. The Tools tab lists all three:
Click search_blog and the right pane shows annotations as four badges and parameters with descriptions:
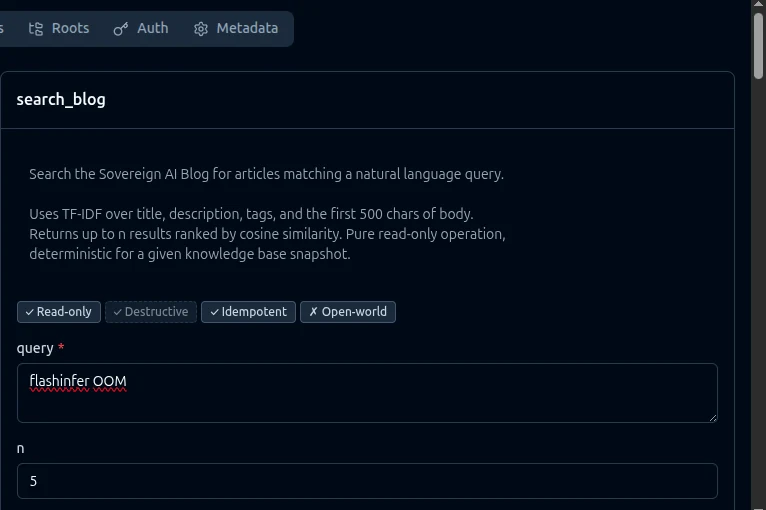
Read-only and Idempotent are green. Destructive and Open-world are red. Exactly what ToolAnnotations(readOnlyHint=True, idempotentHint=True, openWorldHint=False) should render.
Click get_article and scroll the right pane to see the rendered Output Schema:
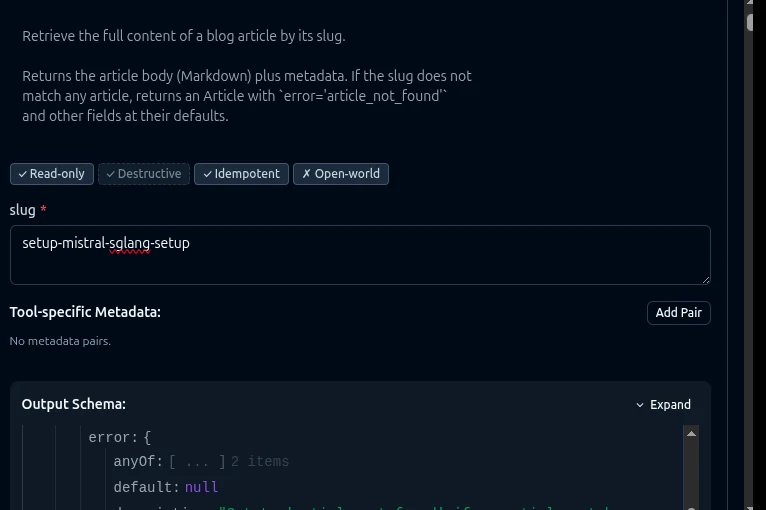
This is the verification that matters. The Inspector shows the actual schema artifacts that the score is computed from. They match the score. If the Inspector shows missing descriptions or a vacuous schema, the score is wrong. If they match, the score is real.
A real call against search_blog with query="flashinfer OOM":
[
{
"slug": "fixes-sglang-vibe-performance-benchmark",
"title": "SGLang on DGX Spark",
"url": "https://sovgrid.org/blog/fixes-sglang-vibe-performance-benchmark",
"description": "How we got Mistral Small 4 119B inference working on...",
"tags": ["fix", "devops"],
"relevance_score": 0.1762,
"quality_score": 254.0,
"quality_style": "smart_infotainment"
}
]Same for diagnose_sglang with attention_backend="flashinfer" and hardware="DGX Spark GB10":
{
"issues": [
{
"severity": "critical",
"param": "attention_backend",
"value": "flashinfer",
"problem": "SM121A architecture is not supported by flashinfer. Causes OOM on first batch.",
"fix": "Use --attention-backend triton",
"source": "https://sovgrid.org/blog/setup-mistral-sglang-setup"
}
],
"warnings": [],
"recommended_config": {
"attention_backend": "triton",
"mem_fraction": 0.75,
"cuda_graph_max_bs": 32,
"image_tag": "lmsysorg/sglang:latest",
"env": {"SGLANG_ENABLE_SPEC_V2": "True"},
"max_running_requests": 16
},
"verdict": "invalid"
}The diagnose tool is pure pattern matching, no LLM. Rule one catches the documented flashinfer + SM121A failure mode and links straight back to the article that documents it. Other rules cover OOM thresholds, incompatible Docker flags, and the missing SGLANG_ENABLE_SPEC_V2 env when EAGLE is enabled.
The three verification gates
Smithery’s listing has three additional checks beyond Quality Score.
The first is automatic: a successful release on submission.
The second is a TXT record on the homepage host. Smithery generates a token of the form smithery-verification=<64-hex-chars> and you add it as an additional TXT record on sovgrid.org. The token is a domain-ownership proof, not a secret: it lives on the public DNS by design and anyone can dig TXT sovgrid.org for it. DNS propagation is the only delay. FlokiNET ↗‘s nameservers had the record on the Google and Cloudflare public resolvers within 60 seconds.
The third is a backlink to Smithery from the README, the homepage, or a custom URL you nominate. The Smithery badge URL convention is specific:
[](https://smithery.ai/servers/cipherfoxie/sovereign-mcp)/servers/ (plural) for the listing page. /badge/ (singular) for the SVG. No @ prefix on the namespace. Wrong format on either, the bot does not match the backlink and verification stays red. Ask me how I know.
What broke and what almost broke
The badge URL was first wrong. The first version used @cipherfoxie/sovereign-mcp and /server/ (singular), copied from a different registry’s pattern. Smithery did not match. Five-minute fix once the canonical format was confirmed in the verification panel.
Glama is currently on hold. The Server-path slug for the same name conflicts with what would be the Connector path slug. Frank from Glama (the same human who replies to support emails) has been emailed; an answer is pending. The awesome-mcp PR is gated on Glama because the bot wants a Glama-score badge in the entry, so that PR is parked for a few days.
The aggregator counter had a silent bug. The MCP path migrated from /mcp to /self-hosted-ai on day one. The NSM aggregator filter still matched only /mcp, so all post-migration calls vanished from the count. Two days of silent under-reporting before the bug surfaced. Fix: parameterize the path list so legacy and current endpoints both count, then add a ?ref= extractor for per-registry attribution. Total cost of finding it: roughly the same as writing this paragraph.
The eeat field was the embarrassing one. The first version of SearchResult returned an eeat_avg: float. The blog frontmatter never had an eeat block, so the field was always 0.0. Misleading to every agent that read it. Fix: replace with quality_score from the editorial-pipeline quality.score field, which is the real signal. The MCP Inspector caught this within five minutes of connecting; the field returned 0 for every result and the bug was instantly visible. The lesson: connect the Inspector before claiming any score is honest.
Things attempted today that did not make this article
- Making
/agentsresponsive in Tor Browser. Removed the entireprefers-color-scheme: lightoverride as collateral damage. Tor users now get pure dark mode whether they wanted it or not. Several--mutedcolor iterations later, gave up at slate-300. - Submitting to Glama via the Server path before realising the Connector path was the right one. Now waiting on Frank to free the namespace. He has been very patient.
- Forgetting that the
eeat_avgfield had been returning 0.0 for eleven days before anyone (me, an MCP Inspector, anyone) noticed. The KB generator looked for aneeatblock in frontmatter that the editorial pipeline never emitted. The blog renders quality-score-aware insights every day. The MCP returned zeros every day. The two systems sat in the same repo and did not speak. - Hexabella vetoing two earlier drafts of this post for being “too eager.” Hexabella is a future agent persona who has not yet drafted a single article herself. Her veto authority is currently aspirational. The mechanism is
git commit --amendwith disappointed body language. - Trying to fast-track an awesome-mcp PR with the
🤖🤖🤖opt-in flag. Successful at submission, but the PR is now blocked by a Glama-badge requirement that Glama itself cannot give me until Frank replies. The bots talk to each other, the humans approve, and somewhere in this chain a queue of merges is waiting on a Tuesday afternoon’s email.
Lessons
A small set of patterns turned a working server into a fully verified listing.
Pydantic everywhere. Inputs go through Annotated[type, Field(description=...)]. Outputs go through BaseModel. FastMCP turns both into the JSON Schema that registries and clients read. Docstrings are not ignored, but they are not what the score measures.
ToolAnnotations is not optional decoration. Read-only, idempotent, destructive, and open-world hints reach the agent. They influence retry policy and trust calibration. Setting them explicitly is closer to honest API design than leaving them undeclared.
A public source repo is non-negotiable for distribution. Smithery’s verification panel requires a backlink. The awesome-mcp PR template requires a GitHub repo. Registry-side scoring uses the source for trust signals. The Sovereign-MCP source was originally in a private Gitea instance. Mirroring it to GitHub took fifteen minutes and unblocked the entire distribution stack.
Path conventions matter. /self-hosted-ai semantically describes what the endpoint is for. /mcp is what FastMCP defaults to. The migration to a semantic path was the right call, but the cost of forgetting to update one downstream consumer (the aggregator) is two days of silent data loss. Always grep the codebase for the old path before declaring a migration done.
Dogfood with the MCP Inspector before claiming the score. Smithery’s number on a dashboard can be wrong (or right for the wrong reasons) and you will not know until an actual client connects. The Inspector is the same protocol, no LLM, no marketing layer. If it shows missing descriptions, the score is dishonest. If it shows the schema as you wrote it, the score is earned.
Why this is not a breakthrough
The honest framing.
A 100/100 score is a number on a Smithery dashboard. The MCP server is one of thousands. Listing exists. Verification is green. None of that is a customer.
The metric that matters for this server is the North Star Metric (NSM): MCP tool calls from external clients per month. Today, that number rounds to zero. The 14 tool calls in the last 30 days are all from a single residential IP doing manual curl tests, namely mine. There has been one meaningful external touch and it was Smithery’s own introspection bot verifying the server.
The hard milestone for this project is set six months out from M1, on 9 December 2026: at least 200 external tool calls per month or the strategy reverses. The Smithery listing is the first credible distribution channel, the GitHub mirror is the first piece of public source on the Internet, and the registry tracking is the first attribution mechanism that distinguishes external pull from internal dogfooding. None of those existed at lunch. All of them existed by dinner. So yes, the day was productive, and yes, the score is real. But the work that earns the M3 milestone is the next 30 days of seeing what (if anything) the Smithery surface actually drives. NSM ticks past zero on the day a real agent calls a real tool and gets back a real answer it could not have invented. Until then, the dashboard is a vanity glass case for a number that has done nothing.
Said differently: this is the day the runway got cleared. Not the day the plane took off.
A guess to laugh at later: by the time someone reads this in 2028, half the directories in this post will be archived (RIP MCP-Get, you were too good for this world), Smithery will have either become the dominant marketplace or pivoted into a chat product, and the awesome-mcp list will be 40,000 entries long with the same ten people maintaining it. The Sovereign-MCP server will probably still be at mcp.sovgrid.org/self-hosted-ai because giving up domains is hard, but Mistral Small 4 will be the new Mistral Small 1, the GB10 will be on a clearance shelf, and diagnose_sglang will be a historical artifact. The schema will still validate.
Glama, less easily impressed
Smithery hands out 100s. Glama hands out a rubric. After the Server-path build went green, Glama’s evaluator wrote this:
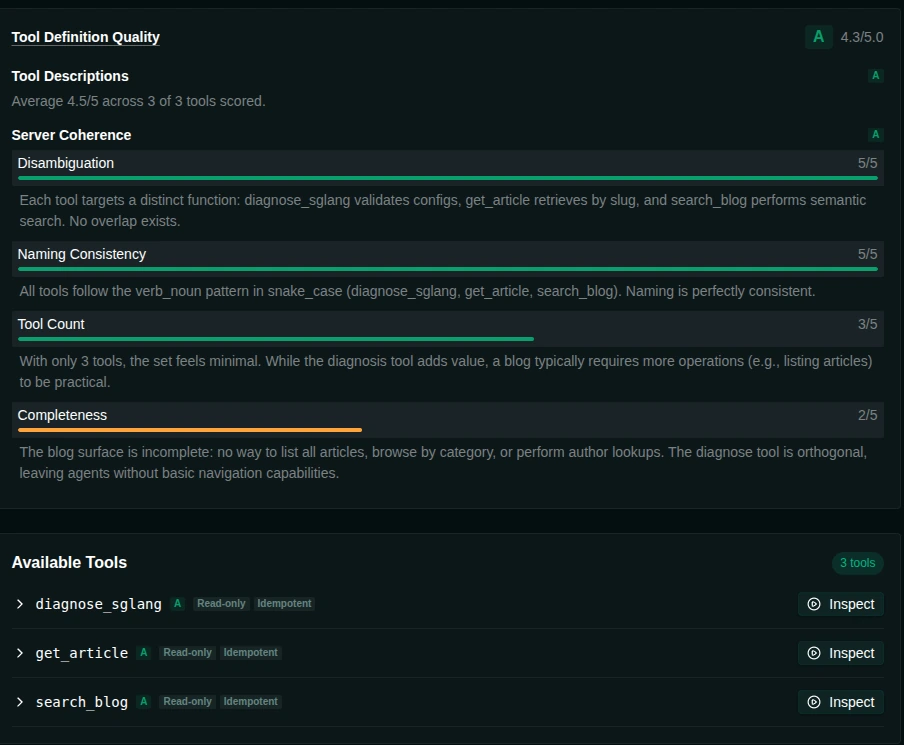
Three sub-scores deserve to be quoted verbatim, because they are the most honest paragraph any registry has produced about this server.
Disambiguation 5/5. Each tool targets a distinct function: diagnose_sglang validates configs, get_article retrieves by slug, and search_blog performs semantic search. No overlap exists.
Naming Consistency 5/5. All tools follow the verb_noun pattern in snake_case (diagnose_sglang, get_article, search_blog). Naming is perfectly consistent.
Tool Count 3/5. With only 3 tools, the set feels minimal. While the diagnosis tool adds value, a blog typically requires more operations (e.g., listing articles) to be practical.
Completeness 2/5. The blog surface is incomplete: no way to list all articles, browse by category, or perform author lookups. The diagnose tool is orthogonal, leaving agents without basic navigation capabilities.
That last paragraph is the right note to read into a script and play back at the next standup. The Smithery dashboard sees a schema and gives a 100. Glama looks at the shape of the surface itself and points out, fairly, that an agent cannot ask “what topics do you cover” or “show me the most recent five articles” without falling back to search_blog with a clumsy query. Those operations are real holes.
The first instinct is to ship four new tools (list_articles, list_tags, articles_by_tag, recent_articles) and watch Glama’s Tool Count and Completeness sub-scores both move. That works as a number on a rubric. It does not necessarily produce a better surface. Three of those four are arguably parameter shapes on search_blog, not new tools:
- “List all articles” is
search_blog(query="", sort="date_desc")once the query is allowed to be empty and a sort dimension exists. - “Articles by tag” is
search_blog(tag="setup"), the same TF-IDF pipeline plus a filter. - “Recent articles” is
search_blog(query="", sort="date_desc", n=5), again a flag away.
Tags themselves are different. There is no honest way to derive “the set of all tags in the corpus” from a search call without scanning the entire result set, which is what list_tags() exists to avoid. So the iteration was one genuinely new tool plus one richer existing one, and both shipped before the article finished:
list_tags(): returns each tag with an article count, sortable by count or alphabetically.search_blog(query, tag=None, sort="relevance"|"date_desc", n): emptyqueryplussort="date_desc"covers pagination and recency, and the optionaltagfilter covers category browsing. The TF-IDF fallback for non-empty queries is unchanged.
That is two tools, not four. Glama’s Tool Count score will be less impressed than it would have been with four. The corpus surface is cleaner. The maintenance footprint is smaller. An agent can now answer all four of the questions the rubric named: list everything by date, browse by tag, get the latest five, see what tags exist. Two tool calls deep at the most. Verified live against the production endpoint with the MCP Inspector before this paragraph was written.
Beyond the holes Glama named, four primitives are sitting in the idea queue, all of them genuinely new shapes rather than parameter shapes on search_blog:
stack_inventory(): return the currently running versions across the Sovereign stack (Mistral build, SGLang nightly tag, Voxtral checkpoint, GB10 driver constraints). Lets an agent ground-truth the system state before suggesting a config change.related_articles(slug, n): graph-style follow-up reading. The agent is already inside one article and wants the natural next two; the query is the slug, not a free-text question.diagnose_voxtral(text, voice)anddiagnose_openclaw(error, config): the diagnostic pattern ofdiagnose_sglangported to the other failure-mode-rich domains in the corpus. Voxtral has a documented forbidden-markup list. OpenClaw has the Mistral-alternating-roles fix. Both are sharp enough to be pattern-matchable without an LLM in the loop.code_blocks_for(slug): return just the code blocks from an article with their language tag and a single line of surrounding context. Agents that want to copy a docker command rarely also want the prose around it.
None of those are urgent. They are filed as “next quiet weekend” tools, after list_tags() and the search extension that fix the actual usability holes.
The honest takeaway: Smithery is a checklist, Glama is a code review. Both are useful. Optimising for either rubric instead of the surface itself is a way to score well and ship something worse.
Try it
claude mcp add sovereign-ai --transport http https://mcp.sovgrid.org/self-hosted-aiOr in any MCP client config:
{
"sovereign-ai": {
"type": "http",
"url": "https://mcp.sovgrid.org/self-hosted-ai"
}
}Free, no auth, 60 requests per minute per IP. Source on GitHub. Listed on Smithery. Inspect at github.com/modelcontextprotocol/inspector.
Stack and disclosures
Nobody sponsored this post. The list below is the equipment receipt, the SaaS receipt, and one affiliate link, in that order. Treat accordingly.
Author: cipherfox.
Editorial-shaped second voice: Hexabella, the project’s strategic-voice agent persona. She has not yet drafted a single article herself but did pre-veto two drafts of this one for being “too eager.” Her veto authority is currently aspirational and the enforcement mechanism is git commit --amend with disappointed body language. Once she ships, you will hear about it.
Hardware (paid for, full price, no relationship): NVIDIA DGX Spark. Bought it. Run a 119B MoE on it daily. Would buy again. The whole sovereign stack is downstream of that one consumer-purchasing decision.
Hosting (paid customer, also affiliate): FlokiNET ↗, no-KYC privacy VPS out of a Romanian DC (HQ Iceland). The link in this paragraph is an affiliate link. If you sign up through it, a small percent kicks back to me. Honest disclosure: this is the only meaningful monetization on the whole site, it pays for roughly nothing right now, and the only reason it exists is that an early-stage sovereign-AI blog needs some business model and “ad-free, no-tracking, V4V plus one affiliate” was the least obnoxious one available. The hosting itself is genuinely good. The DNS panel does what the docs say. Support emails come back from a human. The European jurisdiction is the product, not a feature.
Protocol (free, open spec): Anthropic’s Model Context Protocol. Still young enough that the dev tooling is good and the spec is readable in one sitting.
Server framework (free, MIT): FastMCP by Jeremiah Lowin. The four-line Pydantic refactor in this post would have been a four-day refactor on the bare mcp SDK. Hat tip in the direction of the maintainer.
Inspector tool (free, official): modelcontextprotocol/inspector. The reason this post has screenshots that actually prove the schemas, not just a Smithery score that asserts they exist.
Free tier customer of: Smithery and Glama (Connector path, hosted endpoint). No money has changed hands either direction. Frank at Glama’s support is one of the few in 2026 that answers within hours from an actual human instead of a tier-1 LLM trained on customer-frustration patterns. The Glama listing is the second registry, the Connector path was the right one (the Server path expects a Dockerfile that builds on Glama’s infrastructure, which only makes sense for code users self-host), and the ten-character namespace conflict between Server and Connector paths is now in someone’s backlog as a tracking issue, possibly mine.
The awesome-mcp PR is at punkpeye/awesome-mcp-servers#5645, with the 🤖🤖🤖 opt-in flag for fast-track merging. The bot template required a Glama score badge that only the Server-path listing exposes (Connectors do not currently have score pages). The unblock was a Server-path submission with a 17-line Dockerfile and a placeholder data/knowledge-base.json so Glama could build, start the server, and run introspection. The badge URL is now live at glama.ai/mcp/servers/cipherfoxie/sovereign-mcp/badges/score.svg, the PR has both a Connector and a Server listing of the same MCP, and the bot block is cleared. Side benefit: anyone can docker build the repo locally and self-host an empty version of the same server in two commands.
Reach the author via Nostr or open an issue on the repo. Both replies go to a real human (or to Hexabella, when she finally ships).
Should you actually install this?
A 100/100 score is not a customer. The honest follow-up to this post is Why the Sovereign AI Blog MCP is mostly redundant today (and what would change that), the MVP/POC reality check on when this server starts being worth its install command versus just pasting the blog URL into Claude.